Front-end evolution
简单介绍一下我理解的前端技术演进…
第一阶段:刀耕火种
基本的事件响应机制
- 获取view上的dom
- 对dom进行事件绑定
- 根据事件响应改变视图
1 |
|
频繁的操作dom,性能差,视图view和业务逻辑的js文件揉在一起,维护性差,可读性差,无法复用
第二阶段:前端模块化
- 什么问题导致我们需要前端页面进行组件化?
- 组件化究竟时要解决什么问题?
答:为了解决结构服用,避免产生重复冗余的代码
模块化第一阶段:原始的组建化写法(在全局对象上定义模块的属性和方法)
模块就是实现特定功能的一组方法-所以把不同的函数和变量简单的放在一起就算是一个模块
1 | var name = 'pis'; |
getName getAge方法组成了一个模块,使用的时候直接调用就可以了。
缺点:
污染了全局变量
不能保证在引入其他模块的时候不会发生变量名冲突和方法被overwrite
模块成员之间看不出直接关系
模块化第二阶段:对象的写法
为了解决上面的问题,可以把模块的方法放到一个对象里面,这样就解决了上面的问题
1 | var module = { |
这样所有的模块方法都封装在了对象里面,使用的时候就是调用这个对象的方法就可以了
module.getName() // unclepis
缺点:
暴漏了所有的模块成员
内部的状态可以被外部改写 module.name = ‘eric’
模块化第三阶段:自执行函数
1 |
|
这样的写法使得外部不能获取内部变量,又对外暴漏了模块的接口,所以这就是在es6模块化之前比较主流的模块化写法
自执行函数模块化扩展1:放大模式+自执行函数
如果一个模块很大或者一个模块需要依赖另一个模块,这时候就需要使用放大模式
1 |
|
自执行函数模块化扩展2:
由于浏览器环境中,模块的各个部分通常都是从网上获取的。无法控制资源的加载顺序(requirejs这种amd的方式先不考虑),所以上面引入的module可能在执行的时候还是一个空对象
1 |
|
第三阶段:模块化规范
通过上面的介绍,我们大概知道了,如何使用自执行函数来封装一组方法集合的模块,这样在模块中对外暴漏了接口方法,但是又不污染全局变量,而且不能在外部随意更改模块的内部变量。
虽然这样我们有了模块,可以很方便的服用别人的代码,想要什么功能就加载什么功能,但是每个人的写法可能不一样,所以模块化的规范在社区中慢慢衍生出来…
目前主流的js模块化规范主要包括三个:
- CMD(common module defination)通用模块化定义
- AMD(Asynchronous module defination) 异步模块化定义
CMD
- 09年nodejs项目使得js可以运行在服务器端。这也就标志着js模块化变成正式诞生
- 浏览器环境下网页的复杂性有限,没有模块化问题不是很大,但是运行在服务器端,与操作系统和其他应用程序相互互动,模块化势在必行,否则没发编程
- nodejs的模块系统就是参考commonjs规范实现的,在commonjs中有一个全局性的方法require用于加载模块
1 | var jquery = require('./jquery.js'); |
在服务器端运行的时候,所有的模块都存放在服务器本地的磁盘上,等待的事件也就是硬盘读取的时间
但是如果运行在浏览器上的化,网络的加载可能会使得模块的加载出现⌛️,也就是出现我们常说的页面假死…因此浏览器端不能使用commonjs这种同步加载的方法,
只能采用异步加载的方式,这也就诞生了AMD规范…
AMD
AMD是”Asynchronous Module Definition”的缩写,意思就是”异步模块定义”。
它采用异步方式加载模块,模块的加载不影响它后面语句的运行。
所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
1 | //AMD也采用require()语句加载模块,但是不同于CommonJS,它要求两个参数: |
math.add()与math模块加载不是同步的,浏览器不会发生假死。所以很显然,AMD比较适合浏览器环境。
为什么引入amd?
最早的时候,所有Javascript代码都写在一个文件里面,只要加载这一个文件就够了。后来,代码越来越多,一个文件不够了,必须分成多个文件,依次加载。下面的网页代码,相信很多人都见过。
1 | <script src="1.js"></script> |
这段代码依次加载多个js文件。
这样的写法有很大的缺点。
- 首先,加载的时候,浏览器会停止网页渲染,加载文件越多,网页失去响应的时间就会越长;
- 其次,由于js文件之间存在依赖关系,因此必须严格保证加载顺序(比如上例的1.js要在2.js的前面),依赖性最大的模块一定要放到最后加载,当依赖关系很复杂的时候,代码的编写和维护都会变得困难。
所以amd的规范就是为了解决这个问题:
(1)实现js文件的异步加载,避免网页失去响应;
(2)管理模块之间的依赖性,便于代码的编写和维护。
第四阶段:前端mvc架构
构架模式
如何设计一个程序的结构,就是一个架构模式,属于编程的方法论…(演示需要将demo用http-server跑起来)
mvc构架模式
MVC就是一种常用的软件构架模式,这个模式任务,任何程序,无论简单与否,从结构上都分为三层:分别代表: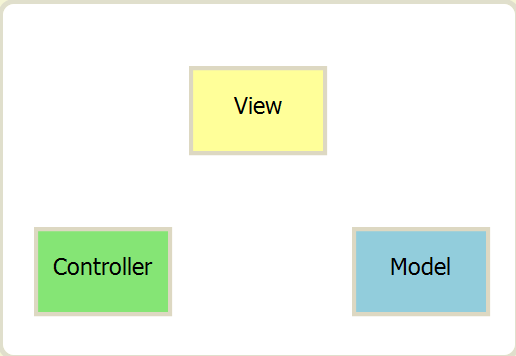
- Modal模型 (数据存储)
- view视图 (用户界面)
- controller控制 (业务逻辑)
step1: View 传送指令到 Controller
step2: Controller 完成业务逻辑后,要求 Model 改变状态
step3: Model 将新的数据发送到 View,用户得到反馈
- 基本的MVC构架模式,所有通信都是单项的
实际的业务构架
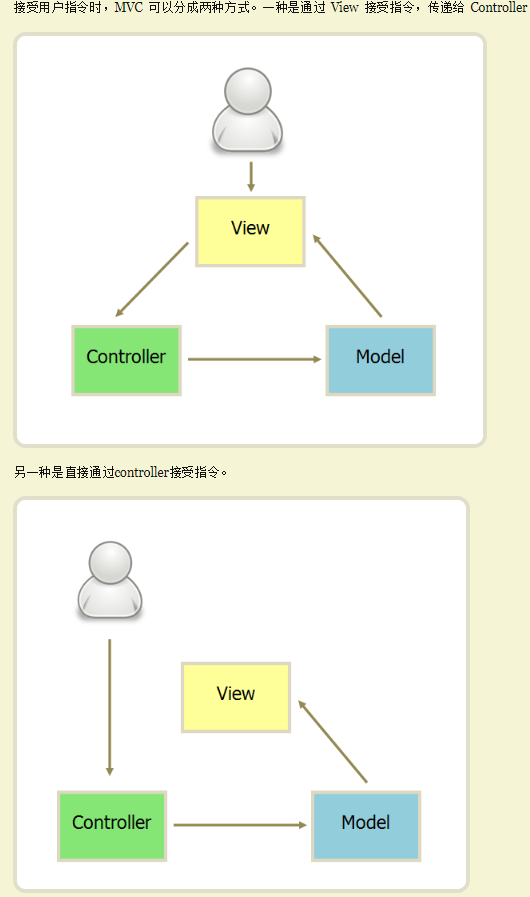
基本上就可以覆盖我们常见的大多数场景
视图层上的用户交互,通过控制器,对数据模型进行操作,然后数据模型的变化也会动态的更新到视图上…
mvp/mvvm构架模式(model view Presenter)/(model view viewModel)
在MVC的基础上,进而演进出了视图view和数据模型model的双向绑定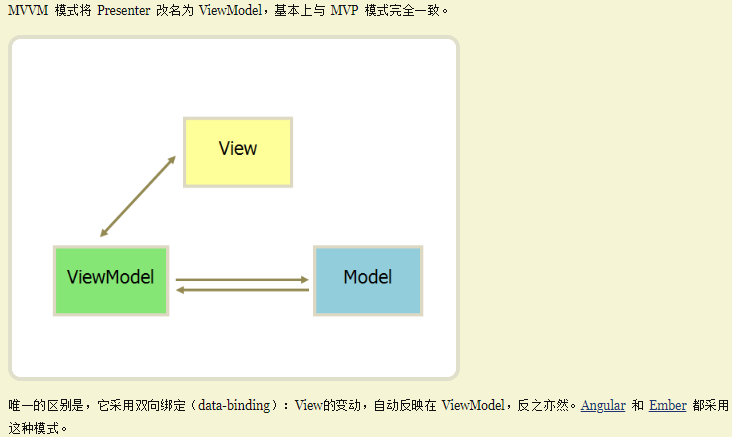
1 |
|
观察者模式和发布订阅模式的有什么区别?
在软件设计中是一个对象,维护一个依赖列表,当任何状态发生改变自动通知它们
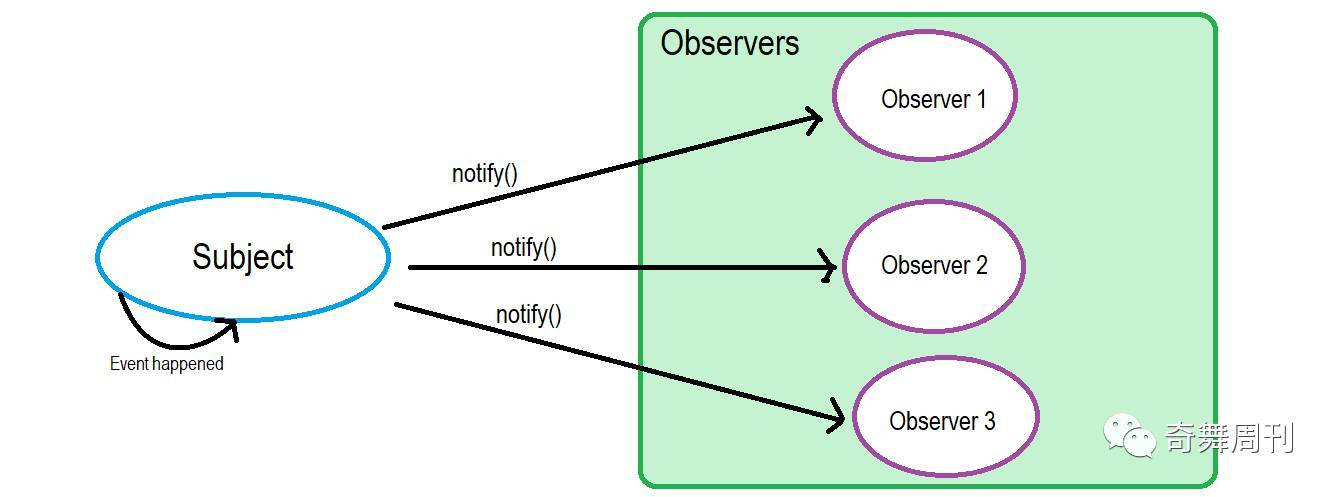
简单的说就好比找工作:
目标公司(Subject)
找工作的人 (Observers)
职位空缺(消息事件)
所以 当职位空缺的时候,目标公司就会通知找工作的人
发布订阅
在发布-订阅模式,消息的发送方,叫做发布者(publishers),消息不会直接发送给特定的接收者(订阅者)。发布者和订阅者不知道对方的存在。需要一个第三方组件,叫做信息中介,它将订阅者和发布者串联起来,它过滤和分配所有输入的消息
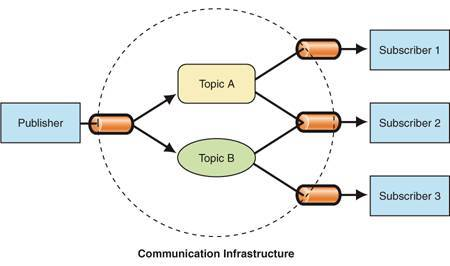
简单的说就好比买卖房子
房主(publisher)就是发布者
房产中介(信息中介)
买房子的人(订阅者)
房主和买房子的人不知道对方的存在,消息通过中介进行传输
区别
在观察者模式中,观察者是知道Subject的,Subject一直保持对观察者进行记录。
然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。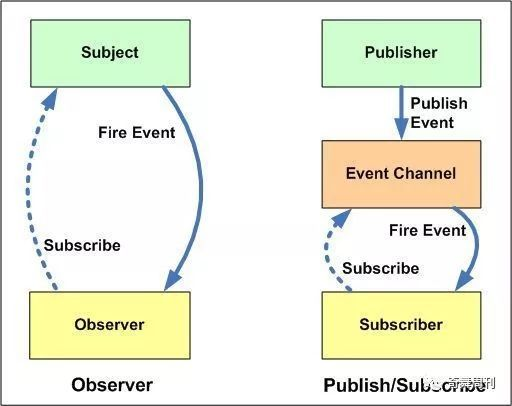
数据劫持和观察者模式
上面的例子,我们通过object.definePropery方法,通过get和set方法对data数据进行了劫持;
然后在数据发生变化的时候,通知给视图上的观察者,来完成视图和数据的关联。
第五阶段:前后端分离+Ajax+restful
标量-序列-映射
从yaml文档中说,从结构上看,所有的数据data最终都可以分解成三种类型
1)第一种是标量(scalar),也就是一个单独的字符串string或者数组numbers
2)第二种是序列(sequence),也就是若干个有序的数据并列在一起,又叫做数组array或是列表list
3)第三种是映射(mapping),也就是一个健值对(key/value),即数据又一个名字,还有一个对应的值,着又称作散列(hash)或是字典(dictionary)
JSON
而21世纪初期,就是一个叫做json的数据格式代替了xml在服务器间进行数据交换传输。什么格式的数据是json?
- 并列数据的集合(数组)用方括号([])表示
- 并列的数据之间用逗号(“,”)分开
- 映射用冒号(“:”)表示
- 映射的集合(对象)用话括号({})表示
上面四条规则,就是Json格式的所有内容。
例如:宁波和利时应用开发部有20人,java开发15人,前端开发4人,测试1人就可以用json表示成
1 | { |
注:js中数组和对象的区别
学习javascript的时候,我曾经一度搞不清楚”数组”(array)和”对象”(object)的根本区别在哪里,两者都可以用来表示数据的集合。
比如有一个数组a=[1,2,3,4],还有一个对象a={0:1,1:2,2:3,3:4},然后你运行alert(a[1]),两种情况下的运行结果是相同的!这就是说,数据集合既可以用数组表示,也可以用对象表示,那么我到底该用哪一种呢?
我后来才知道,数组表示有序数据的集合,而对象表示无序数据的集合。如果数据的顺序很重要,就用数组,否则就用对象。

